1.
某省2023年全年气象灾害预警数据保存在文件“qxyj.xlsx”中,部分数据如图a所示,编写Python程序,统计全年发布次数最多的5种气象预警。
 图a
图a
#导入模块略
df=pd.read_excel("qxyj.xlsx") #读取文件中的数据
(1)
整理数据,删除多余列,划线处代码正确的是:( )(单选,填字母)
(2)
为统计每种气象的预警次数,划线处代码正确的是:____
(3)
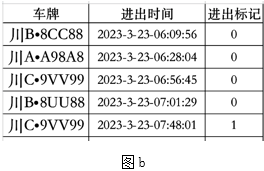
排序后给数据增加“预警等级”列,按照预警名称中的“红橙黄蓝”分别设置等级1234,输出结果如图 b 所示。划线处代码正确的是:( )
(4)
统计全年发布次数最多的5种气象预警,建立图表,如图c所示。请在程序划线处填写合适的代码。
df=df.drop(["预警发布单位","预警发布时间"],____)#删除列
A. ascending=True B. index=True C. axis=0 D. axis=1df_g=df.groupby("预警名称",as_index=False).____ #分组并统计预警次数
df_s= df_g.sort_values("次数"ascending=False) #按"次数"降序排序
A. sum( ) B. count( ) C. min( ) D. mean( ) 图b
图b
df_s["预警等级"]=0#插入新的"预警等级"列,默认值为0
for i in range(len(df_s)):
s=
if s[2]=="红":
df_s.at[i,"预警等级"]=1
elif s[2]=="橙":
df_s.at[i,"预警等级"]=2
elif s[2]=="黄":
df_s.at[i,"预警等级"]=3
elif s[2]=="蓝":
df_s.at[i,"预警等级"]=4
print(df_s)
df_s=df_s.head(5)
A. df_s[i,"预警名称"] B. df_s.at[i,"预警名称"] C. df[i,"预警名称"] D. df.at[i,"预警名称"] 图c
图c
x=df_s.预警名称
y=
plt.bar(x,y) #绘制柱形图
plt.title('发布次数最多的 5 种气象预警')
plt.show() #显示图表
【考点】
编程处理数据与可视化;
能力提升
真题演练

 图c
图c 图 a
图 a 图 b
图 b 图 c
图 c
