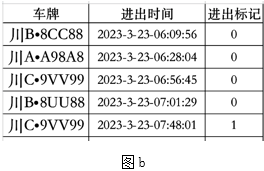
为统计停车场3月份每天的收入(只有驶入或驶出记录的车辆不参与计费),编写Python程序。
①程序段中加框处应填入的代码为(单选,填字母)。
A .data.进出标记[p]==0
B .data.进出标记[p-1]==0 and data.进出标记[p]==1
C .data.进出标记[p+1]==1
D .data.进出标记[p]==0 and data.进出标记[p+1]==1
②请在程序段划线处填入合适的代码。
def catime(t1,t2):
#计算时间t1与时间t2之间的时间差并计算本次停车的费用,函数返回停车费用,代码略。
def readdata(data):
m=len(data)
p=0;cost=0;total=0
while p<m-1:
if ![]() :
:
cost=catime(data.进出时间[p],data.进出时间[p+1])
total+=cost
p+=1
return total
n=31;dic={}
for i in range(1,n+1):
fname="3月"+str(i)+"日.xlsx"
df=pd.read_excel(fname)
df_g=df.groupby("车牌").进出标记.count()
for k in df_g.index:
#只有一条驶入或驶出记录的车辆不参与计费
if :
data=df[df.车牌==k]
dic[i]+=readdata(data)
plt.title("某停车场3月份整体收入图")
plt.bar(dic.keys(),dic.values())
plt.show()
 图c
图c
 图a
图a 图b
图b 图c
图c
 图 a
图 a 图 b
图 b 图 c
图 c
