1.
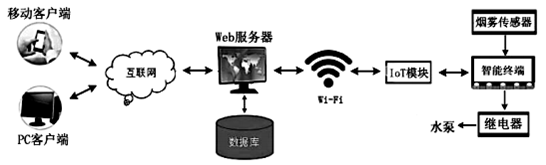
模拟搭建“室内烟雾实时监控系统”,该系统结构示意图如第13题图所示。智能终端接收烟雾传感器采集的数据,IoT模块传送数据到Web服务器并保存到数据库。Web服务器将数据处理的结果经IoT模块传给智能终端,由智能终端启动继电器实现对水泵的控制,并且用户可以通过浏览器访问网页,查看实时数据。
(1)
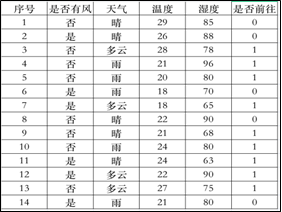
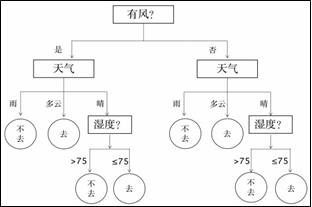
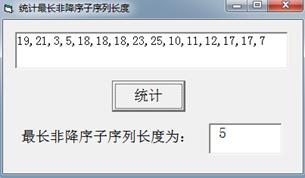
在设计系统的前期准备中,需要确定所需的软硬件配置,这一过程属于 (单选,填字 母:A .需求分析 /B .概要设计 /C .详细设计)
(2)
“室内烟雾实时监控系统”的开发模式是 (单选,填字母:A .B/S模式 /B .C/S模式)
(3)
烟雾传感器每隔1秒采集一次数据,在数据处理的代码中,有函数check(a,b,c)用于检测最近3 次烟雾浓度值a、b、c,若至少有两次超过100,则认为有火情,函数返回True,否则返回False。
(4)
在服务器端,配置IP和端口号的语句为server=Server(host="192.168.1.1",port=80,threaded=True),设置路由函数的语句为@app.route("/warn"),则用户访问的URL为 http://。
(5)
小明用高浓度的烟雾测试系统,通过客户端查看到烟雾浓度数据已连续超过阈值,但是水泵 没有运行,若服务器和终端的代码均正确,则可能的原因是。
下面是check函数的部分代码,请从选项中选择合适的语句完成填空 (单选,填字母)。
def check(a,b,c):
x = a>100; y = b>100; z = c>100
if :
return True
return False
A. (x and y and z) or (x or y or z) B. x and y or x and z or y and z C. x or y and x or z and y or z D. not x or not y or not z【考点】
运算符、基本运算与表达式;
过程与自定义函数;
网络应用模式;
搭建信息系统的前期准备;
能力提升