|
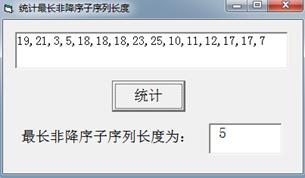
图 1 |
图 2 |
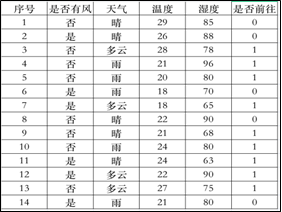
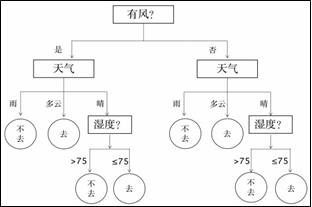
通过了解当天的是否有风、天气、温度和湿度这4个节点参数即可预测当天是否有人来游乐场。不同的节点划分顺序可以绘制不同的决策树,为了选出最优的节点划分顺序,需要采用“信息熵”与“信息增益”指标。
信息熵,又称香农熵,被用来度量信息量的大小,信息熵越大表示信息量越大;
信息增益,表示样本经某节点划分后的信息熵变化大小。我们绘制决策树时应当逐次选择信息增益最大的节点作为当前节点。
对于有n个信息的样本D,记第k个信息发生的概率为𝑝𝑘,信息熵计算公式为E(D)=− ∑𝑛 𝑝𝑘𝑙𝑜𝑔2(𝑝𝑘)
例如游乐场14个样本中“去”(9个)、“不去”(5个),则信息熵 ![]()
若样本按“是否有风”节点划分,“是”(6个,其中3个去,3个不去)信息熵= ![]()
“否”(8个,其中6个去,2个不去)信息熵= ![]() =0.811;经过此节点划分后的信息增益=原始信息熵−按此节点划分后样本信息熵比例和
=0.811;经过此节点划分后的信息增益=原始信息熵−按此节点划分后样本信息熵比例和 ![]() 。
。
def cal(lst): #计算样本 lst 的信息熵
x,y,z=0,len(lst),0 #x表示该样本信息熵,y表示该样本数量,z表示某信息发生的概率
num={}
for i in lst:
if i not in num:
num[i]+=1
for k in num:
z=num[k]/y #计算该信息发生的概率
x-=z*log(z,2) #根据公式计算信息熵,log(b,a)等价于 logab
return x def check(x,y):
#根据节点x,对样本 y 进行划分,返回示例:{'否': [1, 1, 0, 0, 1, 1, 1, 1], '是': [1, 1, 0, 1, 0, 0]},代码略
dic={'是否有风': ['否', '否', '否', '否', '否', '否', '否', '否', '是', '是', '是', '
是', '是', '是'],
'天气': ['多云', '多云', '晴', '晴', '晴', '雨', '雨', '雨', '多云', '多云', '晴', '晴', '雨', '雨'],
'温度': [28, 27, 29, 22, 21, 21, 20, 24, 18, 22, 26, 24, 18, 21], '湿度': [78, 75, 85, 90, 68, 96, 80, 80, 65, 90, 88, 63, 70, 80],
'是否前往': [1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0]} xm=list(dic.keys())
entropy=cal(dic[xm[-1]]) #调用函数计算样本原始信息熵 entropy #计算各节点信息增益
m=0;p=""
col=xm[:-1] #“是否前往”是结果项,不参与计算
for i in col:
size=len(dic[i]);entropy_1=0
zyb= #调用函数对样本 dic 按照当前节点进行划分
for j in zyb: #根据划分情况逐个求子样本信息熵并按比例累加
entropy_1+=len(zyb[j])/size*cal(zyb[j])
zy=entropy-entropy_1
print(i,"的信息增益:",zy)
if zy>m: #计算最大信息增益与信息增益最大的节点
m=zy
print("信息增益最大的节点:",p)