请回答下列问题:
A.df.groupby("地市",as_index=False).count()
B.df.groupby("地市",as_index=False).sum()
C.df.groupby("地市",as_index=True).mean()
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("T14.xlsx")
df1 = ① # 计算各地市不同年龄段的人数
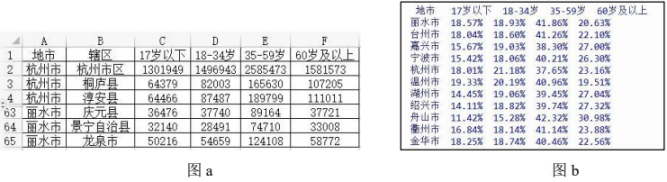
print ("地 市17 岁以下 18-34 岁 35-59 岁 60 岁及以上")
#“df1.values.tolist()”实现将 df1 转换为二维列表。列表中每个元素包含 5 个数
#据项,分别对应地市名称和该地市 4 个年龄段人数总计,如['丽水市', 501421, ...]
df2=df1.values.tolist()
x,y = [],[]
for area in df2:
for c in range(len(area)):
if c == 0:
x.append(area[0])
print(area[0], end=" ?")
else:
sm = sum(area[1:]) #sum 函数实现对序列求和
t= ②
print('%.2f' %(t), end="% ?") #按设置格式输出
if c == 4:
y.append(t)
print()
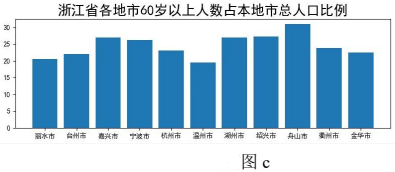
plt.title("浙江省各地市 60 岁以上人数占本地市总人口比例", fontsize=24)
plt.bar(x, y)
#绘制 60 岁及以上人数占本地市总人口比例柱形图
#设置绘图参数,显示如图 c 所示,代码略。
#df1为二维列表,列表中每个元素包含6个数据项,内容如图a所示;函数返回值dfs格式同题(1)二维列表 df2
def mygroupby(df1):
dfs=[] #创建一个空列表 dfs
for row in df1:
if n>0:
for j in range(n):
if row[0]==dfs[j][0]:
break
if n==0 or row[0] != dfs[j][0]:
dfs.append([row[0],0,0,0,0])
j=n
for k in range(2,len(row)):
return dfs