1.
K-近邻分类算法是指:一个样本在特征空间中的
k 个最相邻的样本中的大多数属于某一类别,则该样本也属于这个类别。如图所示有一坐标轴,横纵坐标分别为一部电影中搞笑镜头的个数和打斗镜头的个数。动作片中打斗镜头较多,喜剧片中搞笑镜头较多, 因此体现在坐标轴中,动作片集中在左上,喜剧片集中在右下。现要实现如下功能:输入某部电影的搞笑镜头和打斗镜头数目后,输出可能的类型,并在坐标轴中体现,如图三角形所示。
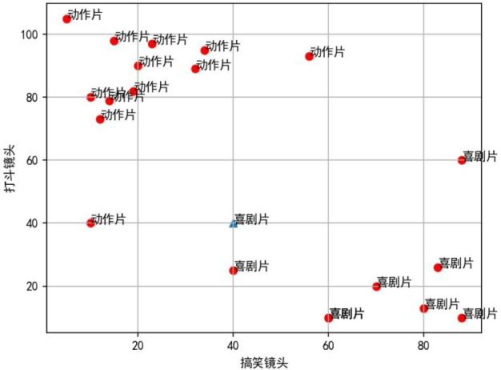
例如:
①输入搞笑镜头40和打斗镜头40:
②计算点(40,40)和其余所有点的距离(两点间的距离计算公式:
③将所有样本按照距离排序;
④假设k=3,取前k个距离的样本;
⑤统计出在前k个距离中,出现频次最多的类别,则(40,40)就属于该类别,可能是喜剧片。
(1)
上述举例的步骤中,主要是以(选填:A .自然语言/B .流程图/C .伪代码)方式在描述 k近邻算法
(2)
步骤③中,要将所有距离排序,但未说明按何种方式按什么顺序排序,主要违反了算法特征中的(选填:A .有穷性/B .可行性/C .确定性)
(3)
若将步骤⑤重新描述为:统计出在前 k 个距离中,出现频次最多的类别,若在前 k 个距离中,喜剧片出现的多,则(40,40)可能是喜剧片;否则(40,40)则是动作片。这主要体现了算法三要素的(选填:A .数据/B .运算/C .控制转移)。
(4)
假设通过升序排序后的列表 d 前几个数据对应的影片类型为:动作片,喜剧片,喜剧片,动作片,动作片...。当 k 取 3 时,则输入的影片对应的影片类型为(选填: A .动作片/B .喜剧片)
(5)
请将步骤②用代码的形式表示: import sqrt from math
x=int(input('请输入搞笑镜头数:'))
y=int(input('请输入打斗镜头数:'))
d=[ ] #用于存储距离
#已将所有样本横坐标保存至列表 ybx,可用 ybx[i]表示某一点横坐标
#已将所有样本纵坐标保存至列表yby,可用yby[i]表示某一点纵坐标
#即样本点坐标可用(ybx[i],yby[i])表示
for i in range(len(ybx)): #通过循环,计算所有样本点到点(x,y)的距离
d[i]=
(提示:sqrt()函数为开根函数,sqrt(3)即为根号 3)
【考点】
算法的基本概念与特征;
算法的常用表示方法;
编程处理数据与可视化;
算法的要素;
能力提升

